匈牙利算法详解(含时间复杂度)


寻找二部图最大匹配的匈牙利数学家埃德蒙德斯在1965年提出的一个简化的最大流算法。该算法根据二部图匹配这个问题的特点将最大流算法进行了简化,提高了效率。
普通的最大流算法一般都是基于带权网络模型的,二部图匹配问题不需要区分图中的源点和汇点,也不关心边的方向,因此不需要复杂的网络图模型,这就是匈牙利算法简化的原因。
正是因为这个原因,匈牙利算法成为一种很简单的二分匹配算法,其基本流程是:
所谓的增广路径取反操作,就是把增广路径上奇数编号的边加入到已知匹配中,并把增广路径上偶数编号的边从已知匹配中删除。每做一次“取反”操作,得到的匹配就比原匹配多一个。
匈牙利算法的思路就是不停地寻找增广路径,增加匹配的个数,当不能再找到增广路径时,算法就结束了,得到的匹配就是最大匹配。
增广路径的起点总是在二部图的左边,因此寻找增广路径的算法总是从一侧的顶点开始,逐个顶点搜索。从 Xi 顶点开始搜索增广路径的流程如下:
到现在为止,匈牙利算法的流程已经很清楚了,现在我们来给出实现代码。
首先定义求最大匹配的数据结构,这个数据结构要能表示二部图的边的关系,还要能体现最终的增广路径结果,给出如下定义:
从 Xi 寻找增广路径的算法实现如下:
输出结果的时候,需要结合 Y 集合中的顶点索引输出,如果需要以 X 集合的顺序输出结果,需要反向转换,转换的方法非常简单:
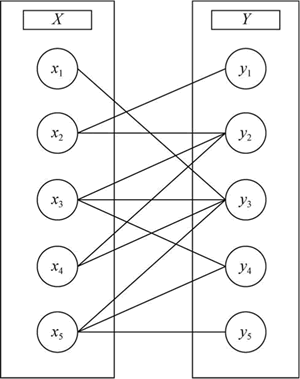
图 1 二部图
我们用图 1 中的二部图数据初始化 GRAPH_MATCH 中的顶点关系表 edge,然后调用 Hungary_Match() 函数得到一组匹配:
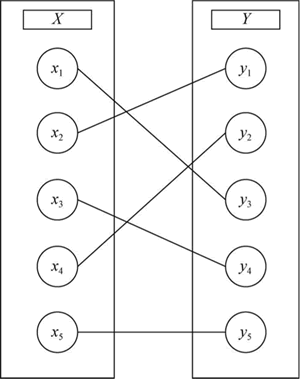
图 2 完美匹配
匈牙利算法的实现以顶点集合 V 为基础,每次 X 集合中选一个顶点 Xi 做增广路径的起点搜索增广路径。搜索增广路径需要遍历边集 E 内的所有边,遍历方法可以采用深度优先遍历(DFS),也可以采用广度优先遍历(BFS),无论什么方法,其时间复杂度都是
匈牙利算法每个顶点 Vi 只能选择一次,因此算法的整体时间复杂度是
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。
普通的最大流算法一般都是基于带权网络模型的,二部图匹配问题不需要区分图中的源点和汇点,也不关心边的方向,因此不需要复杂的网络图模型,这就是匈牙利算法简化的原因。
正是因为这个原因,匈牙利算法成为一种很简单的二分匹配算法,其基本流程是:
将图 G 最大匹配初始化为空
while(从Xi点开始在图G中找到新的增广路径)
{
将增广路径假如到最大匹配中;
}
输出图 G 的最大匹配;
- 路径中边的条数是奇数;
- 路径的起点在二部图的左半边,终点在二部图的右半边;
- 路径上的点一个在左半边,一个在右半边,交替出现,整条路径上没有重复的点;
- 只有路径的起点和终点都是未覆盖的点,路径上其他的点都已经配对;
- 对路径上的边按照顺序编号,所有奇数编号的边都不在已知的匹配中,所有偶数编号的边都在已知的匹配中;
- 对增广路径进行“取反”操作,新的匹配数就比已知匹配数增加一个,也就是说,可以得到一个更大的匹配;
所谓的增广路径取反操作,就是把增广路径上奇数编号的边加入到已知匹配中,并把增广路径上偶数编号的边从已知匹配中删除。每做一次“取反”操作,得到的匹配就比原匹配多一个。
匈牙利算法的思路就是不停地寻找增广路径,增加匹配的个数,当不能再找到增广路径时,算法就结束了,得到的匹配就是最大匹配。
增广路径的起点总是在二部图的左边,因此寻找增广路径的算法总是从一侧的顶点开始,逐个顶点搜索。从 Xi 顶点开始搜索增广路径的流程如下:
while(从 Xi 的邻接表中找到下一个关联顶点 Yj)
{
if(顶点 Yj 不在增广路径上)
{
将 Yj 加入增广路径;
if(Yj 是未覆盖点或者从与 Yj 相关连的顶点(Xk)能找到增广路径)
{
将 Yj 的关联顶点修改为 Xi;
从顶点 Xi 开始有增广路径,返回 true;
}
}
从顶点 Xi 开始没有增广路径,返回 false;
}
到现在为止,匈牙利算法的流程已经很清楚了,现在我们来给出实现代码。
首先定义求最大匹配的数据结构,这个数据结构要能表示二部图的边的关系,还要能体现最终的增广路径结果,给出如下定义:
typedef struct tagMaxMatch
{
int edge[UNIT_COUNT][UNIT_COUNT];
bool on_path[UNIT_COUNT];
int path[UNIT_COUNT];
int max_match;
}GRAPH_MATCH;
edge 是顶点与边的关系表,用来表示二部图,on_path 用来表示顶点 Yj 是否已经在当前搜索过程中形成的增广路径上了,path 是当前找到的增广路径,max_match 是当前增广路径中边的条数,当算法结束时,如果 max_match 不等于顶点个数,说明有顶点不在最大增广路径上,也就是说,找不到能覆盖所有点的增广路径,此二部图没有最大匹配。从 Xi 寻找增广路径的算法实现如下:
bool FindAugmentPath(GRAPH_MATCH *match, int xi)
{
for(int yj = 0; yj < UNIT_COUNT; yj++)
{
if((match->edge[xi][yj] == 1) && !match->on_path[yj])
{
match->on_path[yj] = true;
if( (match->path[yj] == -1)
|| FindAugmentPath(match, match->path[yj]) )
{
match->path[yj] = xi;
return true;
}
}
}
return false;
}
算法实现基本上是按照之前的算法流程实现的,不需要做特别说明,唯一需要注意的是 path 中存放增广路径的方式。读者可能已经注意到了,存放的方式是以 Y 集合中的顶点为索引存放,其值是对应的关联顶点在 X 集合中的索引。搜索是按照 X 集合中的顶点索引进行的,增广路径以 Y 集合中的顶点为索引存储,关系是反的。输出结果的时候,需要结合 Y 集合中的顶点索引输出,如果需要以 X 集合的顺序输出结果,需要反向转换,转换的方法非常简单:
int path[UNIT_COUNT] = { 0 };
for(int i = 0; i < match->max_match; i++)
{
path[match->path[i]] = i;
}
转换后 path 中就是以 X 集合的顺序存放的结果。结合之前给出的匈牙利算法基本流程,最后给出匈牙利算法的入口函数实现:
bool Hungary_Match(GRAPH_MATCH *match)
{
for(int xi = 0; xi < UNIT_COUNT; xi++)
{
if(FindAugmentPath(match, xi))
{
match->max_match++;
}
ClearOnPathSign(match);
}
return (match->max_match == UNIT_COUNT);
}
每完成一个顶点的搜索,需要重置 Y 集合中相关顶点的 on_path 标志,ClearOnPathSign() 函数就负责干这个事情。
图 1 二部图
我们用图 1 中的二部图数据初始化 GRAPH_MATCH 中的顶点关系表 edge,然后调用 Hungary_Match() 函数得到一组匹配:
X1<--->Y3
X2<--->Y1
X3<--->Y4
X4<--->Y2
X5<--->Y5
图 2 完美匹配
匈牙利算法的实现以顶点集合 V 为基础,每次 X 集合中选一个顶点 Xi 做增广路径的起点搜索增广路径。搜索增广路径需要遍历边集 E 内的所有边,遍历方法可以采用深度优先遍历(DFS),也可以采用广度优先遍历(BFS),无论什么方法,其时间复杂度都是
O(E)。匈牙利算法每个顶点 Vi 只能选择一次,因此算法的整体时间复杂度是
O(V*E),总的来说,是一个相当高效的算法。声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。

 ICP备案:
ICP备案: 公安部网络备案:
公安部网络备案: