大白话带你玩转链表(超级肝,新手必看)


在这篇文章里,我将带你搞清楚以下几个问题:
- 链表是什么
- 链表的基本操作(增删查改)
- 双向链表是什么
- 双向链表基本操作
- 循环链表是什么
- 双向循环链表是什么
1、链表是什么?
链表又称单链表、链式存储结构,用于存储逻辑关系为“一对一”的数据。和顺序表不同,使用链表存储数据,不强制要求数据在内存中集中存储,各个元素可以分散存储在内存中。例如,使用链表存储 {1,2,3},各个元素在内存中的存储状态可能是:

图 1 数据分散存储在内存中
可以看到,数据不仅没有集中存放,在内存中的存储次序也是混乱的。那么,链表是如何存储数据间逻辑关系的呢?
链表存储数据间逻辑关系的实现方案是:为每一个元素配置一个指针,每个元素的指针都指向自己的直接后继元素,如下图所示:

图 2 链表的实现方案
显然,我们只需要记住元素 1 的存储位置,通过它的指针就可以找到元素 2,通过元素 2 的指针就可以找到元素 3,以此类推,各个元素的先后次序一目了然。
像图 2 这样,数据元素随机存储在内存中,通过指针维系数据之间“一对一”的逻辑关系,这样的存储结构就是链表。
结点(节点)
在链表中,每个数据元素都配有一个指针,这意味着,链表上的每个“元素”都长下图这个样子:很多教材中,也将“结点”写成“节点”,它们是一个意思。

图 3 链表中的结点结构
数据域用来存储元素的值,指针域用来存放指针。数据结构中,通常将图 3 这样的整体称为结点。
也就是说,链表中实际存放的是一个一个的结点,数据元素存放在各个结点的数据域中。举个简单的例子,图 2 中 {1,2,3} 的存储状态用链表表示,如下图所示:

图 4 链表中的结点
在 C 语言中,可以用结构体表示链表中的结点,例如:
typedef struct link{
char elem; //代表数据域
struct link * next; //代表指针域,指向直接后继元素
}Link;
我们习惯将结点中的指针命名为 next,因此指针域又常称为“Next 域”。
头结点、头指针和首元结点
图 4 所示的链表并不完整,一个完整的链表应该由以下几部分构成:- 头指针:一个和结点类型相同的指针,它的特点是:永远指向链表中的第一个结点。上文提到过,我们需要记录链表中第一个元素的存储位置,就是用头指针实现。
-
结点:链表中的节点又细分为头结点、首元结点和其它结点:
- 头结点:某些场景中,为了方便解决问题,会故意在链表的开头放置一个空结点,这样的结点就称为头结点。也就是说,头结点是位于链表开头、数据域为空(不利用)的结点。
- 首元结点:指的是链表开头第一个存有数据的结点。
- 其他节点:链表中其他的节点。
也就是说,一个完整的链表是由头指针和诸多个结点构成的。每个链表都必须有头指针,但头结点不是必须的。
例如,创建一个包含头结点的链表存储 {1,2,3},如下图所示:
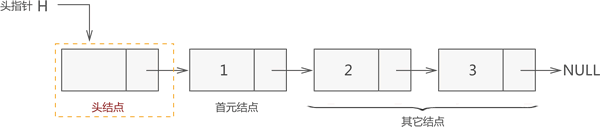
图 5 完整的链表示意图
再次强调,头指针永远指向链表中的第一个结点。换句话说,如果链表中包含头结点,那么头指针指向的是头结点,反之头指针指向首元结点。
链表的创建
创建一个链表,实现步骤如下:- 定义一个头指针;
- 创建一个头结点或者首元结点,让头指针指向它;
- 每创建一个结点,都令其直接前驱结点的指针指向它。
例如,创建一个存储 {1,2,3,4} 且无头节点的链表,C 语言实现代码为:
Link* initLink() {
int i;
//1、创建头指针
Link* p = NULL;
//2、创建首元结点
Link* temp = (Link*)malloc(sizeof(Link));
temp->elem = 1;
temp->next = NULL;
//头指针指向首元结点
p = temp;
//3、每创建一个结点,都令其直接前驱结点的指针指向它
for (i = 2; i < 5; i++) {
//创建一个结点
Link* a = (Link*)malloc(sizeof(Link));
a->elem = i;
a->next = NULL;
//每次 temp 指向的结点就是 a 的直接前驱结点
temp->next = a;
//temp指向下一个结点(也就是a),为下次添加结点做准备
temp = temp->next;
}
return p;
}
再比如,创建一个存储 {1,2,3,4} 且含头节点的链表,则 C 语言实现代码为:
Link* initLink() {
int i;
//1、创建头指针
Link* p = NULL;
//2、创建头结点
Link* temp = (Link*)malloc(sizeof(Link));
temp->elem = 0;
temp->next = NULL;
//头指针指向头结点
p = temp;
//3、每创建一个结点,都令其直接前驱结点的指针指向它
for (i = 1; i < 5; i++) {
//创建一个结点
Link* a = (Link*)malloc(sizeof(Link));
a->elem = i;
a->next = NULL;
//每次 temp 指向的结点就是 a 的直接前驱结点
temp->next = a;
//temp指向下一个结点(也就是a),为下次添加结点做准备
temp = temp->next;
}
return p;
}
链表的使用
对于创建好的链表,我们可以依次获取链表中存储的数据,例如:
#include <stdio.h>
#include <stdlib.h>
//链表中节点的结构
typedef struct link {
int elem;
struct link* next;
}Link;
Link* initLink() {
int i;
//1、创建头指针
Link* p = NULL;
//2、创建头结点
Link* temp = (Link*)malloc(sizeof(Link));
temp->elem = 0;
temp->next = NULL;
//头指针指向头结点
p = temp;
//3、每创建一个结点,都令其直接前驱结点的指针指向它
for (i = 1; i < 5; i++) {
//创建一个结点
Link* a = (Link*)malloc(sizeof(Link));
a->elem = i;
a->next = NULL;
//每次 temp 指向的结点就是 a 的直接前驱结点
temp->next = a;
//temp指向下一个结点(也就是a),为下次添加结点做准备
temp = temp->next;
}
return p;
}
void display(Link* p) {
Link* temp = p;//temp指针用来遍历链表
//只要temp指向结点的next值不是NULL,就执行输出语句。
while (temp) {
Link* f = temp;//准备释放链表中的结点
printf("%d ", temp->elem);
temp = temp->next;
free(f);
}
printf("\n");
}
int main() {
Link* p = NULL;
printf("初始化链表为:\n");
//创建链表{1,2,3,4}
p = initLink();
//输出链表中的数据
display(p);
return 0;
}
程序中创建的是带头结点的链表,头结点的数据域存储的是元素 0,因此最终的输出结果为:
0 1 2 3 4
如果不想输出头结点的值,可以将 p->next 作为实参传递给 display() 函数。如果程序中创建的是不带头结点的链表,最终的输出结果应该是:
1 2 3 4
2、链表的基本操作(增删查改)
接下来继续讲解链表的一些基本操作,包括向链表中添加数据、删除链表中的数据、查找和更改链表中的数据。首先,创建一个带头结点的链表,链表中存储着 {1,2,3,4}:
//链表中节点的结构
typedef struct link {
int elem;
struct link* next;
}Link;
Link* initLink() {
int i;
//1、创建头指针
Link* p = NULL;
//2、创建头结点
Link* temp = (Link*)malloc(sizeof(Link));
temp->elem = 0;
temp->next = NULL;
//头指针指向头结点
p = temp;
//3、每创建一个结点,都令其直接前驱结点的指针指向它
for (i = 1; i < 5; i++) {
//创建一个结点
Link* a = (Link*)malloc(sizeof(Link));
a->elem = i;
a->next = NULL;
//每次 temp 指向的结点就是 a 的直接前驱结点
temp->next = a;
//temp指向下一个结点(也就是a),为下次添加结点做准备
temp = temp->next;
}
return p;
}
链表插入元素
同顺序表一样,向链表中增添元素,根据添加位置不同,可分为以下 3 种情况:- 插入到链表的头部,作为首元节点;
- 插入到链表中间的某个位置;
- 插入到链表的最末端,作为链表中最后一个结点;
对于有头结点的链表,3 种插入元素的实现思想是相同的,具体步骤是:
- 将新结点的 next 指针指向插入位置后的结点;
- 将插入位置前结点的 next 指针指向插入结点;
{1,2,3,4} 的基础上分别实现在头部、中间、尾部插入新元素 5,其实现过程如图 1 所示: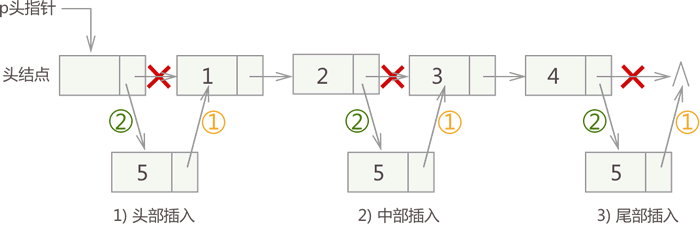
图 1 带头结点链表插入元素的 3 种情况
从图中可以看出,虽然新元素的插入位置不同,但实现插入操作的方法是一致的,都是先执行步骤 1 ,再执行步骤 2。实现代码如下:
void insertElem(Link* p, int elem, int add) {
int i;
Link* c = NULL;
Link* temp = p;//创建临时结点temp
//首先找到要插入位置的上一个结点
for (i = 1; i < add; i++) {
temp = temp->next;
if (temp == NULL) {
printf("插入位置无效\n");
return;
}
}
//创建插入结点c
c = (Link*)malloc(sizeof(Link));
c->elem = elem;
//① 将新结点的 next 指针指向插入位置后的结点
c->next = temp->next;
//② 将插入位置前结点的 next 指针指向插入结点;
temp->next = c;
}
注意:链表插入元素的操作必须是先步骤 1,再步骤 2;反之,若先执行步骤 2,除非再添加一个指针,作为插入位置后续链表的头指针,否则会导致插入位置后的这部分链表丢失,无法再实现步骤 1。
对于没有头结点的链表,在头部插入结点比较特殊,需要单独实现。
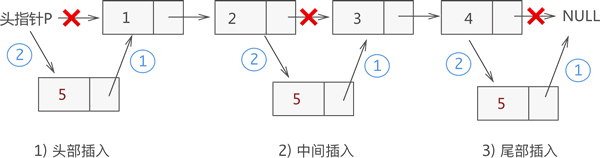
图 2 不带头结点链表插入元素的 3 种情况
和 2)、3) 种情况相比,由于链表没有头结点,在头部插入新结点,此结点之前没有任何结点,实现的步骤如下:
- 将新结点的指针指向首元结点;
- 将头指针指向新结点。
实现代码如下:
Link* insertElem(Link* p, int elem, int add) {
if (add == 1) {
//创建插入结点c
Link* c = (Link*)malloc(sizeof(Link));
c->elem = elem;
c->next = p;
p = c;
return p;
}
else {
int i;
Link* c = NULL;
Link* temp = p;//创建临时结点temp
//首先找到要插入位置的上一个结点
for (i = 1; i < add-1; i++) {
temp = temp->next;
if (temp == NULL) {
printf("插入位置无效\n");
return p;
}
}
//创建插入结点c
c = (Link*)malloc(sizeof(Link));
c->elem = elem;
//向链表中插入结点
c->next = temp->next;
temp->next = c;
return p;
}
}
注意当 add==1 成立时,形参指针 p 的值会发生变化,因此需要它的新值作为函数的返回值返回。
链表删除元素
从链表中删除指定数据元素时,实则就是将存有该数据元素的节点从链表中摘除。对于有头结点的链表来说,无论删除头部(首元结点)、中部、尾部的结点,实现方式都一样,执行以下三步操作:
- 找到目标元素所在结点的直接前驱结点;
- 将目标结点从链表中摘下来;
- 手动释放结点占用的内存空间;
从链表上摘除目标节点,只需找到该节点的直接前驱节点 temp,执行如下操作:
temp->next=temp->next->next;例如,从存有
{1,2,3,4} 的链表中删除存储元素 3 的结点,则此代码的执行效果如图 3 所示: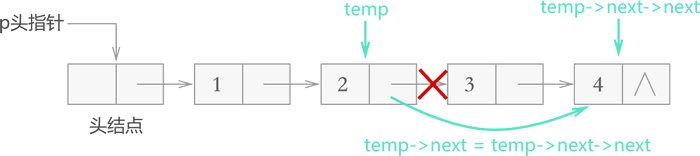
图 3 带头结点链表删除元素
实现代码如下:
//p为原链表,elem 为要删除的目标元素
int delElem(Link* p, int elem) {
Link* del = NULL, *temp = p;
int find = 0;
//1、找到目标元素的直接前驱结点
while (temp->next) {
if (temp->next->elem == elem) {
find = 1;
break;
}
temp = temp->next;
}
if (find == 0) {
return -1;//删除失败
}
else
{
//标记要删除的结点
del = temp->next;
//2、将目标结点从链表上摘除
temp->next = temp->next->next;
//3、释放目标结点
free(del);
return 1;
}
}
对于不带头结点的链表,需要单独考虑删除首元结点的情况,删除其它结点的方式和图 3 完全相同,如下图所示:
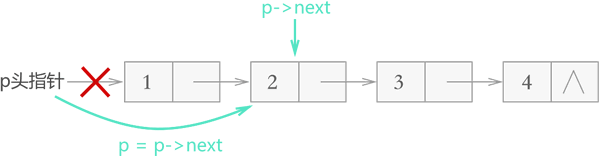
图 4 不带头结点链表删除结点
实现代码如下:
//p为原链表,elem 为要删除的目标元素
int delElem(Link** p, int elem) {
Link* del = NULL, *temp = *p;
//删除首元结点需要单独考虑
if (temp->elem == elem) {
(*p) = (*p)->next;
free(temp);
return 1;
}
else
{
int find = 0;
//1、找到目标元素的直接前驱结点
while (temp->next) {
if (temp->next->elem == elem) {
find = 1;
break;
}
temp = temp->next;
}
if (find == 0) {
return -1;//删除失败
}
else
{
//标记要删除的结点
del = temp->next;
//2、将目标结点从链表上摘除
temp->next = temp->next->next;
//3、释放目标结点
free(del);
return 1;
}
}
}
函数返回 1 时,表示删除成功;返回 -1,表示删除失败。注意,该函数的形参 p 为二级指针,调用时需要传递链表头指针的地址。
链表查找元素
在链表中查找指定数据元素,最常用的方法是:从首元结点开始依次遍历所有节点,直至找到存储目标元素的结点。如果遍历至最后一个结点仍未找到,表明链表中没有存储该元素。因此,链表中查找特定数据元素的 C 语言实现代码为:
//p为原链表,elem表示被查找元素
int selectElem(Link* p, int elem) {
int i = 1;
//带头结点,p 指向首元结点
p = p->next;
while (p) {
if (p->elem == elem) {
return i;
}
p = p->next;
i++;
}
return -1;//返回-1,表示未找到
}
注意第 5 行代码,对于有结点的链表,需要先将 p 指针指向首元结点;反之,对于不带头结点的链表,注释掉第 5 行代码即可。链表更新元素
更新链表中的元素,只需通过遍历找到存储此元素的节点,对节点中的数据域做更改操作即可。直接给出链表中更新数据元素的 C 语言实现代码:
//p 为有头结点的链表,oldElem 为旧元素,newElem 为新元素
int amendElem(Link* p, int oldElem, int newElem) {
p = p->next;
while (p) {
if (p->elem == oldElem) {
p->elem = newElem;
return 1;
}
p = p->next;
}
return -1;
}
函数返回 1,表示更改成功;返回数字 -1,表示更改失败。如果是没有头结点的链表,直接删除第 3 行代码即可。总结
以上内容详细介绍了对链表中数据元素做"增删查改"的实现过程及 C 语言代码,最后给大家一段完整的代码,实现对有头结点链表的“增删查改”:
#include <stdio.h>
#include <stdlib.h>
//链表中节点的结构
typedef struct link {
int elem;
struct link* next;
}Link;
Link* initLink() {
int i;
//1、创建头指针
Link* p = NULL;
//2、创建头结点
Link* temp = (Link*)malloc(sizeof(Link));
temp->elem = 0;
temp->next = NULL;
//头指针指向头结点
p = temp;
//3、每创建一个结点,都令其直接前驱结点的指针指向它
for (i = 1; i < 5; i++) {
//创建一个结点
Link* a = (Link*)malloc(sizeof(Link));
a->elem = i;
a->next = NULL;
//每次 temp 指向的结点就是 a 的直接前驱结点
temp->next = a;
//temp指向下一个结点(也就是a),为下次添加结点做准备
temp = temp->next;
}
return p;
}
//p为链表,elem为目标元素,add为要插入的位置
void insertElem(Link* p, int elem, int add) {
int i;
Link* c = NULL;
Link* temp = p;//创建临时结点temp
//首先找到要插入位置的上一个结点
for (i = 1; i < add; i++) {
temp = temp->next;
if (temp == NULL) {
printf("插入位置无效\n");
return;
}
}
//创建插入结点c
c = (Link*)malloc(sizeof(Link));
c->elem = elem;
//① 将新结点的 next 指针指向插入位置后的结点
c->next = temp->next;
//② 将插入位置前结点的 next 指针指向插入结点;
temp->next = c;
}
//p为原链表,elem 为要删除的目标元素
int delElem(Link* p, int elem) {
Link* del = NULL, *temp = p;
int find = 0;
//1、找到目标元素的直接前驱结点
while (temp->next) {
if (temp->next->elem == elem) {
find = 1;
break;
}
temp = temp->next;
}
if (find == 0) {
return -1;//删除失败
}
else
{
//标记要删除的结点
del = temp->next;
//2、将目标结点从链表上摘除
temp->next = temp->next->next;
//3、释放目标结点
free(del);
return 1;
}
}
//p为原链表,elem表示被查找元素
int selectElem(Link* p, int elem) {
int i = 1;
//带头结点,p 指向首元结点
p = p->next;
while (p) {
if (p->elem == elem) {
return i;
}
p = p->next;
i++;
}
return -1;//返回-1,表示未找到
}
//p 为有头结点的链表,oldElem 为旧元素,newElem 为新元素
int amendElem(Link* p, int oldElem, int newElem) {
p = p->next;
while (p) {
if (p->elem == oldElem) {
p->elem = newElem;
return 1;
}
p = p->next;
}
return -1;
}
//输出链表中各个结点的元素
void display(Link* p) {
p = p->next;
while (p) {
printf("%d ", p->elem);
p = p->next;
}
printf("\n");
}
//释放链表
void Link_free(Link* p) {
Link* fr = NULL;
while (p->next)
{
fr = p->next;
p->next = p->next->next;
free(fr);
}
free(p);
}
int main() {
Link* p = initLink();
printf("初始化链表为:\n");
display(p);
printf("在第 3 的位置上添加元素 6:\n");
insertElem(p, 6, 3);
display(p);
printf("删除元素4:\n");
delElem(p, 4);
display(p);
printf("查找元素 2:\n");
printf("元素 2 的位置为:%d\n", selectElem(p, 2));
printf("更改元素 1 的值为 6:\n");
amendElem(p, 1, 6);
display(p);
Link_free(p);
return 0;
}
执行结果为:
初始化链表为:
1 2 3 4
在第 3 的位置上添加元素 6:
1 2 6 3 4
删除元素4:
1 2 6 3
查找元素 2:
元素 2 的位置为:2
更改元素 1 的值为 6:
6 2 6 3
3、双向链表是什么
目前我们所学到的链表,各个节点都只包含一个指针(游标),且都统一指向直接后继节点,这类链表又统称为单向链表或单链表。虽然单链表能 100% 存储逻辑关系为 "一对一" 的数据,但在解决某些实际问题时,单链表的执行效率并不高。例如,若实际问题中需要频繁地查找某个结点的前驱结点,使用单链表存储数据显然没有优势,因为单链表的强项是从前往后查找目标元素,不擅长从后往前查找元素。
解决此类问题,可以建立双向链表(简称双链表)。
双向链表是什么
从名字上理解双向链表,即链表是 "双向" 的,如图 1 所示:
图 1 双向链表结构示意图
“双向”指的是各节点之间的逻辑关系是双向的,头指针通常只设置一个。
从图 1 中可以看到,双向链表中各节点包含以下 3 部分信息(如图 2 所示):- 指针域:用于指向当前节点的直接前驱节点;
- 数据域:用于存储数据元素。
- 指针域:用于指向当前节点的直接后继节点;

图 2 双向链表的节点构成
因此,双链表的节点结构用 C 语言实现为:
typedef struct line{
struct line * prior; //指向直接前趋
int data;
struct line * next; //指向直接后继
}Line;
双向链表的创建
同单链表相比,双链表仅是各节点多了一个用于指向直接前驱的指针域。因此,我们可以在单链表的基础轻松实现对双链表的创建。需要注意的是,与单链表不同,双链表创建过程中,每创建一个新节点都要与其前驱节点建立两次联系,分别是:
- 将新节点的 prior 指针指向直接前驱节点;
- 将直接前驱节点的 next 指针指向新节点;
这里给出创建双向链表的 C 语言实现代码:
Line* initLine(Line* head) {
Line* list = NULL;
head = (Line*)malloc(sizeof(Line));//创建链表第一个结点(首元结点)
head->prior = NULL;
head->next = NULL;
head->data = 1;
list = head;
for (int i = 2; i <= 5; i++) {
//创建并初始化一个新结点
Line* body = (Line*)malloc(sizeof(Line));
body->prior = NULL;
body->next = NULL;
body->data = i;
//直接前趋结点的next指针指向新结点
list->next = body;
//新结点指向直接前趋结点
body->prior = list;
list = list->next;
}
return head;
}
我们可以尝试着在 main 函数中输出创建的双链表,C 语言代码如下:
#include <stdio.h>
#include <stdlib.h>
typedef struct line {
struct line* prior; //指向直接前趋
int data;
struct line* next; //指向直接后继
}Line;
Line* initLine(Line* head) {
int i;
Line* list = NULL;
head = (Line*)malloc(sizeof(Line));//创建链表第一个结点(首元结点)
head->prior = NULL;
head->next = NULL;
head->data = 1;
list = head;
for (i = 2; i <= 5; i++) {
//创建并初始化一个新结点
Line* body = (Line*)malloc(sizeof(Line));
body->prior = NULL;
body->next = NULL;
body->data = i;
//直接前趋结点的next指针指向新结点
list->next = body;
//新结点指向直接前趋结点
body->prior = list;
list = list->next;
}
return head;
}
//输出链表中的数据
void display(Line* head) {
Line* temp = head;
while (temp) {
//如果该节点无后继节点,说明此节点是链表的最后一个节点
if (temp->next == NULL) {
printf("%d\n", temp->data);
}
else {
printf("%d <-> ", temp->data);
}
temp = temp->next;
}
}
//释放链表中结点占用的空间
void free_line(Line* head) {
Line* temp = head;
while (temp) {
head = head->next;
free(temp);
temp = head;
}
}
int main()
{
//创建一个头指针
Line* head = NULL;
//调用链表创建函数
head = initLine(head);
//输出创建好的链表
display(head);
//显示双链表的优点
printf("链表中第 4 个节点的直接前驱是:%d", head->next->next->next->prior->data);
free_line(head);
return 0;
}
程序运行结果:
1 <-> 2 <-> 3 <-> 4 <-> 5
链表中第 4 个节点的直接前驱是:3
4、双向链表基本操作
前面学习了如何创建一个双向链表,本节学习有关双向链表的一些基本操作,即如何在双向链表中添加、删除、查找或更改数据元素。本节知识基于已熟练掌握双向链表创建过程的基础上,我们继续上节所创建的双向链表来学习本节内容,创建好的双向链表如图 1 所示:

图 1 双向链表示意图
双向链表添加节点
根据数据添加到双向链表中的位置不同,可细分为以下 3 种情况:1) 添加至表头
将新数据元素添加到表头,只需要将该元素与表头元素建立双层逻辑关系即可。换句话说,假设新元素节点为 temp,表头节点为 head,则需要做以下 2 步操作即可:
- temp->next=head; head->prior=temp;
- 将 head 移至 temp,重新指向新的表头;
例如,将新元素 7 添加至双链表的表头,则实现过程如图 2 所示:

图 2 添加元素至双向链表的表头
2) 添加至表的中间位置
同单链表添加数据类似,双向链表中间位置添加数据需要经过以下 2 个步骤,如图 3 所示:- 新节点先与其直接后继节点建立双层逻辑关系;
- 新节点的直接前驱节点与之建立双层逻辑关系;
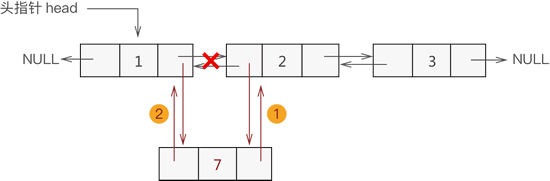
图 3 双向链表中间位置添加数据元素
3) 添加至表尾
与添加到表头是一个道理,实现过程如下(如图 4 所示):- 找到双链表中最后一个节点;
- 让新节点与最后一个节点进行双层逻辑关系;
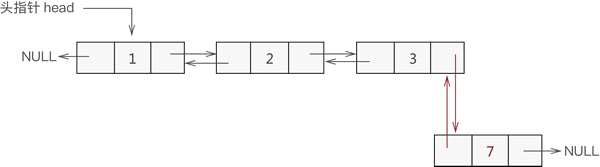
图 4 双向链表尾部添加数据元素
因此,我们可以试着编写双向链表添加数据的 C 语言代码,参考代码如下:
Line* insertLine(Line* head, int data, int add) {
//新建数据域为data的结点
Line* temp = (Line*)malloc(sizeof(Line));
temp->data = data;
temp->prior = NULL;
temp->next = NULL;
//插入到链表头,要特殊考虑
if (add == 1) {
temp->next = head;
head->prior = temp;
head = temp;
}
else {
int i;
Line* body = head;
//找到要插入位置的前一个结点
for (i = 1; i < add - 1; i++) {
body = body->next;
//只要 body 不存在,表明插入位置输入错误
if (!body) {
printf("插入位置有误!\n");
return head;
}
}
//判断条件为真,说明插入位置为链表尾,实现第 2 种情况
if (body && (body->next == NULL)) {
body->next = temp;
temp->prior = body;
}
else {
//第 2 种情况的具体实现
body->next->prior = temp;
temp->next = body->next;
body->next = temp;
temp->prior = body;
}
}
return head;
}
双向链表删除节点
和添加结点的思想类似,在双向链表中删除目标结点也分为 3 种情况。1) 删除表头结点
删除表头结点的过程如下图所示: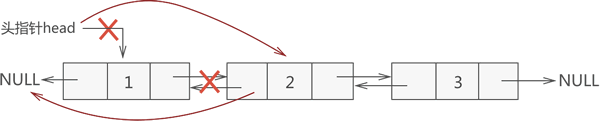
图 5 删除双链表表头元素
删除表头结点的实现过程是:
- 新建一个指针指向表头结点;
- 断开表头结点和其直接后续结点之间的关联,更改 head 头指针的指向,同时将其直接后续结点的 prior 指针指向 NULL;
- 释放表头结点占用的内存空间。
2) 删除表中结点
删除表中结点的过程如下图所示:
图 6 删除表中结点
- 找到目标结点,新建一个指针指向改结点;
- 将目标结点从链表上摘除;
- 释放该结点占用的内存空间。
3) 删除表尾结点
删除表尾结点的过程如下图所示:
图 7 删除表尾结点
删除表尾结点的实现过程是:
- 找到表尾结点,新建一个指针指向该结点;
- 断点表尾结点和其直接前驱结点的关联,并将其直接前驱结点的 next 指针指向 NULL;
- 释放表尾结点占用的内存空间。
双向链表删除节点的 C 语言实现代码如下:
//删除结点的函数,data为要删除结点的数据域的值
Line* delLine(Line* head, int data) {
Line* temp = head;
while (temp) {
if (temp->data == data) {
//删除表头结点
if (temp->prior == NULL) {
head = head->next;
if (head) {
head->prior = NULL;
temp->next = NULL;
}
free(temp);
return head;
}
//删除表中结点
if (temp->prior && temp->next) {
temp->next->prior = temp->prior;
temp->prior->next = temp->next;
free(temp);
return head;
}
//删除表尾结点
if (temp->next == NULL) {
temp->prior->next = NULL;
temp->prior = NULL;
free(temp);
return head;
}
}
temp = temp->next;
}
printf("表中没有目标元素,删除失败\n");
return head;
}
双向链表查找节点
通常情况下,双向链表和单链表一样都仅有一个头指针。因此,双链表查找指定元素的实现同单链表类似,也是从表头依次遍历表中元素。C 语言实现代码为:
//head为原双链表,elem表示被查找元素
int selectElem(line * head,int elem){
//新建一个指针t,初始化为头指针 head
line * t=head;
int i=1;
while (t) {
if (t->data==elem) {
return i;
}
i++;
t=t->next;
}
//程序执行至此处,表示查找失败
return -1;
}
双向链表更改节点
更改双链表中指定结点数据域的操作是在查找的基础上完成的。实现过程是:通过遍历找到存储有该数据元素的结点,直接更改其数据域即可。实现此操作的 C 语言实现代码如下:
//更新函数,其中,add 表示要修改的元素,newElem 为新数据的值
void amendElem(Line* p, int oldElem, int newElem) {
Line* temp = p;
int find = 0;
//找到要修改的目标结点
while (temp)
{
if (temp->data == oldElem) {
find = 1;
break;
}
temp = temp->next;
}
//成功找到,则进行更改操作
if (find == 1) {
temp->data = newElem;
return;
}
//查找失败,输出提示信息
printf("链表中未找到目标元素,更改失败\n");
}
总结
这里给出双链表中对数据进行 "增删查改" 操作的完整实现代码:
#include <stdio.h>
#include <stdlib.h>
typedef struct line {
struct line* prior; //指向直接前趋
int data;
struct line* next; //指向直接后继
}Line;
Line* initLine(Line* head) {
int i;
Line* list = NULL;
head = (Line*)malloc(sizeof(Line));//创建链表第一个结点(首元结点)
head->prior = NULL;
head->next = NULL;
head->data = 1;
list = head;
for (i = 2; i <= 5; i++) {
//创建并初始化一个新结点
Line* body = (Line*)malloc(sizeof(Line));
body->prior = NULL;
body->next = NULL;
body->data = i;
//直接前趋结点的next指针指向新结点
list->next = body;
//新结点指向直接前趋结点
body->prior = list;
list = list->next;
}
return head;
}
void display(Line* head) {
Line* temp = head;
while (temp) {
//如果该节点无后继节点,说明此节点是链表的最后一个节点
if (temp->next == NULL) {
printf("%d\n", temp->data);
}
else {
printf("%d <-> ", temp->data);
}
temp = temp->next;
}
}
//删除结点的函数,data为要删除结点的数据域的值
Line* delLine(Line* head, int data) {
Line* temp = head;
while (temp) {
if (temp->data == data) {
//删除表头结点
if (temp->prior == NULL) {
head = head->next;
if (head) {
head->prior = NULL;
temp->next = NULL;
}
free(temp);
return head;
}
//删除表中结点
if (temp->prior && temp->next) {
temp->next->prior = temp->prior;
temp->prior->next = temp->next;
free(temp);
return head;
}
//删除表尾结点
if (temp->next == NULL) {
temp->prior->next = NULL;
temp->prior = NULL;
free(temp);
return head;
}
}
temp = temp->next;
}
printf("表中没有目标元素,删除失败\n");
return head;
}
//head为原双链表,elem表示被查找元素
int selectElem(Line* head, int elem) {
//新建一个指针t,初始化为头指针 head
Line* t = head;
int i = 1;
while (t) {
if (t->data == elem) {
return i;
}
i++;
t = t->next;
}
//程序执行至此处,表示查找失败
return -1;
}
//更新函数,其中,add 表示要修改的元素,newElem 为新数据的值
void amendElem(Line* p, int oldElem, int newElem) {
Line* temp = p;
int find = 0;
//找到要修改的目标结点
while (temp)
{
if (temp->data == oldElem) {
find = 1;
break;
}
temp = temp->next;
}
//成功找到,则进行更改操作
if (find == 1) {
temp->data = newElem;
return;
}
//查找失败,输出提示信息
printf("链表中未找到目标元素,更改失败\n");
}
//释放链表中结点占用的内存空间
void free_line(Line* head) {
Line* temp = head;
while (temp) {
head = head->next;
free(temp);
temp = head;
}
}
int main()
{
//创建一个头指针
Line* head = NULL;
//调用链表创建函数
head = initLine(head);
printf("创建好的双向链表为:\n");
display(head);
printf("删除元素 2:\n");
head = delLine(head, 2);
display(head);
printf("元素 3 的位置是:%d\n", selectElem(head, 3));
printf("表中的元素 3 改为 6:\n");
amendElem(head, 3, 6);
display(head);
free_line(head);
return 0;
}
程序执行结果为:
创建好的双向链表为:
1 <-> 2 <-> 3 <-> 4 <-> 5
删除元素 2:
1 <-> 3 <-> 4 <-> 5
元素 3 的位置是:2
表中的元素 3 改为 6:
1 <-> 6 <-> 4 <-> 5
5、循环链表是什么
无论是静态链表还是动态链表,有时在解决具体问题时,需要我们对其结构进行稍微地调整。比如,可以把链表的两头连接,使其成为了一个环状链表,通常称为循环链表。和它名字的表意一样,只需要将表中最后一个结点的指针指向头结点,链表就能成环儿,如图 1 所示。

需要注意的是,虽然循环链表成环状,但本质上还是链表,因此在循环链表中,依然能够找到头指针和首元节点等。循环链表和普通链表相比,唯一的不同就是循环链表首尾相连,其他都完全一样。
循环链表实现约瑟夫环
约瑟夫环问题,是一个经典的循环链表问题,题意是:已知 n 个人(分别用编号 1,2,3,…,n 表示)围坐在一张圆桌周围,从编号为 k 的人开始顺时针报数,数到 m 的那个人出列;他的下一个人又从 1 开始,还是顺时针开始报数,数到 m 的那个人又出列;依次重复下去,直到圆桌上剩余一个人。如图 2 所示,假设此时圆周周围有 5 个人,要求从编号为 3 的人开始顺时针数数,数到 2 的那个人出列:
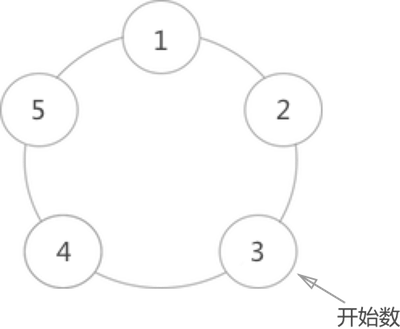
图 2 循环链表实现约瑟夫环
出列顺序依次为:
- 编号为 3 的人开始数 1,然后 4 数 2,所以 4 先出列;
- 4 出列后,从 5 开始数 1,1 数 2,所以 1 出列;
- 1 出列后,从 2 开始数 1,3 数 2,所以 3 出列;
- 3 出列后,从 5 开始数 1,2 数 2,所以 2 出列;
- 最后只剩下 5 自己,所以 5 胜出。
约瑟夫环问题有多种变形,比如顺时针转改为逆时针等,虽然问题的细节有多种变数,但解决问题的中心思想是一样的,即使用循环链表。
通过以上的分析,我们可以尝试编写 C 语言代码,完整代码如下所示:
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int number;
struct node * next;
}person;
person * initLink(int n) {
int i = 0;
person * head = NULL, *cyclic = NULL;
head = (person*)malloc(sizeof(person));
head->number = 1;
head->next = NULL;
cyclic = head;
for (i = 2; i <= n; i++) {
person * body = (person*)malloc(sizeof(person));
body->number = i;
body->next = NULL;
cyclic->next = body;
cyclic = cyclic->next;
}
cyclic->next = head;//首尾相连
return head;
}
void findAndKillK(person * head, int k, int m) {
person * p = NULL;
person * tail = head;
//找到链表第一个结点的上一个结点,为删除操作做准备
while (tail->next != head) {
tail = tail->next;
}
p = head;
//找到编号为k的人
while (p->number != k) {
tail = p;
p = p->next;
}
//从编号为k的人开始,只有符合p->next==p时,说明链表中除了p结点,所有编号都出列了,
while (p->next != p) {
int i = 0;
//找到从p报数1开始,报m的人,并且还要知道数m-1de人的位置tail,方便做删除操作。
for (i = 1; i < m; i++) {
tail = p;
p = p->next;
}
tail->next = p->next;//从链表上将p结点摘下来
printf("出列人的编号为:%d\n", p->number);
free(p);
p = tail->next;//继续使用p指针指向出列编号的下一个编号,游戏继续
}
printf("出列人的编号为:%d\n", p->number);
free(p);
}
int main() {
int n = 0, k = 0, m = 0;
person * head = NULL;
printf("输入圆桌上的人数:");
scanf("%d", &n);
head = initLink(n);
printf("从第几个人开始报数(k>1且k<%d):", n);
scanf("%d", &k);
printf("数到几的人出列:");
scanf("%d", &m);
findAndKillK(head, k, m);
return 0;
}
输出结果:
输入圆桌上的人数:5
从第几个人开始报数(k>1且k<5):3
数到几的人出列:2
出列人的编号为:4
出列人的编号为:1
出列人的编号为:3
出列人的编号为:2
出列人的编号为:5
总结
循环链表和动态链表唯一不同在于它的首尾连接,这也注定了在使用循环链表时,附带最多的操作就是遍历链表。在遍历的过程中,尤其要注意循环链表虽然首尾相连,但并不表示该链表没有第一个节点和最后一个结点。所以,不要随意改变头指针的指向。
6、双向循环链表是什么
我们知道,单链表通过首尾连接可以构成单向循环链表,如图 1 所示:
图 1 单向循环链表示意图
同样,双向链表也可以进行首尾连接,构成双向循环链表。如图 2 所示:

图 2 双向循环链表示意图
解决某些问题,可能既需要正向遍历数据,又需要逆向遍历数据,这时就可以考虑使用双向循环链表。
双向循环链表的创建
创建双向循环链表,只需在创建完成双向链表的基础上,将其首尾节点进行双向连接即可。C 语言实现代码如下:
//创建双向循环链表
Line* initLine(Line* head) {
int i;
Line* list = NULL;
head = (Line*)malloc(sizeof(Line));//创建链表第一个结点(首元结点)
head->prior = NULL;
head->next = NULL;
head->data = 1;
list = head;
for (i = 2; i <= 3; i++) {
//创建并初始化一个新结点
Line* body = (Line*)malloc(sizeof(Line));
body->prior = NULL;
body->next = NULL;
body->data = i;
//直接前趋结点的next指针指向新结点
list->next = body;
//新结点指向直接前趋结点
body->prior = list;
list = list->next;
}
//通过以上代码,已经创建好双线链表,接下来将链表的首尾节点进行双向连接
list->next=head;
head->prior=list;
return head;
}
通过向 main 函数中调用 initLine 函数,就可以成功创建一个存储有
{1,2,3} 数据的双向循环链表,其完整的 C 语言实现代码为:
#include <stdio.h>
#include <stdlib.h>
typedef struct line {
struct line* prior; //指向直接前趋
int data;
struct line* next; //指向直接后继
}Line;
//创建双向循环链表
Line* initLine(Line* head) {
int i;
Line* list = NULL;
head = (Line*)malloc(sizeof(Line));//创建链表第一个结点(首元结点)
head->prior = NULL;
head->next = NULL;
head->data = 1;
list = head;
for (i = 2; i <= 3; i++) {
//创建并初始化一个新结点
Line* body = (Line*)malloc(sizeof(Line));
body->prior = NULL;
body->next = NULL;
body->data = i;
//直接前趋结点的next指针指向新结点
list->next = body;
//新结点指向直接前趋结点
body->prior = list;
list = list->next;
}
//通过以上代码,已经创建好双线链表,接下来将链表的首尾节点进行双向连接
list->next = head;
head->prior = list;
return head;
}
//输出链表中的数据
void display(Line* head) {
Line* temp = head;
//由于是循环链表,所以当遍历指针temp指向的下一个节点是head时,证明此时已经循环至链表的最后一个节点
while (temp->next != head) {
if (temp->next == NULL) {
printf("%d\n", temp->data);
}
else {
printf("%d->", temp->data);
}
temp = temp->next;
}
//输出循环链表中最后一个节点的值
printf("%d", temp->data);
}
//释放链表中结点占用的空间
void free_line(Line* head) {
Line* temp = NULL;
//切断循环
head->prior->next = NULL;
//从第一个结点开始,依次 free
temp = head;
while (temp) {
head = head->next;
free(temp);
temp = head;
}
}
int main()
{
//创建一个头指针
Line* head = NULL;
//调用链表创建函数
head = initLine(head);
//输出创建好的链表
display(head);
//手动释放链表占用的内存
free_line(head);
return 0;
}
程序输出结果如下:
1->2->3
声明:当前文章为本站“玩转C语言和数据结构”官方原创,由国家机构和地方版权局所签发的权威证书所保护。

 ICP备案:
ICP备案: 公安部网络备案:
公安部网络备案: