【2026最新】Ollama下载、安装和使用一篇搞定(附官网安装包)
Ollama 是一款免费的本地大语言模型运行工具,它的核心功能是让你在个人电脑上轻松下载、运行和管理各种开源 AI 大模型,比如 Llama、Mistral、Gemma、Qwen 等。不需要联网,不需要租云服务器,只要你的电脑有合适的配置,Ollama 就能把强大的 AI 模型带到你的本地环境中运行。Ollama安装包下载地址:Ollama安装包(官网正版)
同领域的本地 AI 运行工具各有特点,简单对比一下:
| 软件 | 是否免费 | 主要特点 | 适合人群 |
|---|---|---|---|
| Ollama | 免费、开源 | 一键运行、模型管理方便、跨平台 | 绝大多数本地 AI 用户首选 |
| LM Studio | 免费 | 图形化界面、内置模型搜索 | 更喜欢 GUI 操作的用户 |
| llama.cpp | 免费、开源 | 底层运行时、性能最优化 | 开发者、深度定制用户 |
| GPT4All | 免费、开源 | 安装简单、自带聊天界面 | 新手入门、教育场景 |
Ollama 最大的优势在于把复杂的模型部署过程简化到了极致。以前要跑一个大模型,需要配置 Python 环境、安装 PyTorch、下载模型文件、写推理代码……一套流程下来能劝退绝大多数人。Ollama 直接把这一切打包成一条命令,安装后打开终端,输入一行命令就能下载并启动模型,几分钟内就能开始对话。
截止到发文,Ollama 的最新稳定版是 Ollama 0.30.7,新增了多模态模型支持、并发请求处理能力,优化了内存占用和推理速度,支持 Windows、macOS 和 Linux 三大平台。
Ollama下载
Ollama安装包下载地址:Ollama安装包(官网正版)软件完全免费开源,没有任何使用限制。下载时需要注意,Ollama 提供了针对不同操作系统的安装包。Windows 用户下载 .exe 安装程序,macOS 用户下载 .dmg 安装包,Linux 用户执行如下命令安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh
Ollama安装
Ollama的安装过程非常简单,基本上就是标准的软件安装流程。1)我使用的是 Windows 系统,下载 .exe 格式的可执行文件。双击这个文件启动安装程序:
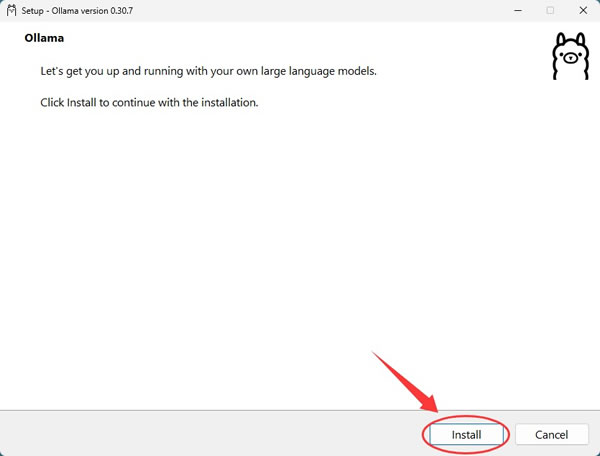
2)直接点击 Install,开始安装:
3)安装完成后,点击"Cancel"按钮退出安装程序,Ollama 会自动启动:
修改Ollama模型存储路径
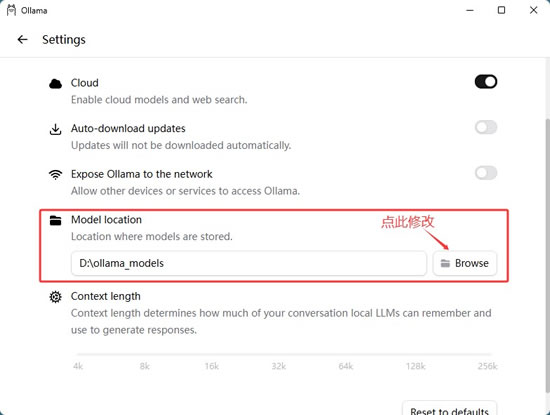
Ollama 默认将模型存储到 C 盘(通常为 C:\Users\Administrator\.ollama\models),这对 C 盘可用容量有限的小伙伴非常不友好,我们可以手动将其修改为其它非系统盘。非 Windows 平台用户可以跳过这一步。
修改的方法很简单,进入“Settings”界面,参照下图完成修改:
Ollama下载模型
Ollama 主要通过命令行界面进行操作。打开终端(Windows 用户可以使用 PowerShell 或 CMD),就可以开始使用 Ollama 了。访问 Ollama 官网模型库:https://ollama.com/library,找到你想使用的 AI 模型,比如 deepseek:
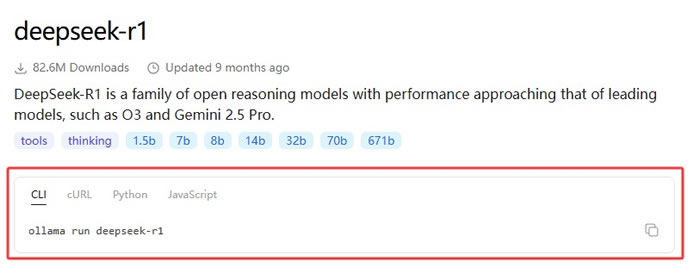
点击 deepseek-r1,进入下图的页面,就能看到运行它的命令,是不是很简单:
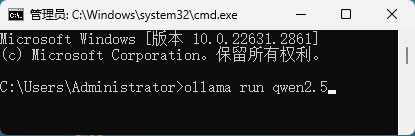
这里以 qwen2.5 模型为例,在 CMD 窗口执行如下命令:
ollama run qwen2.5
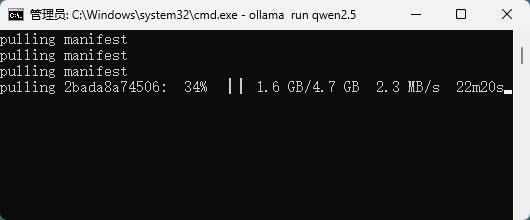
耐心等待模型下载完,下载过程可能需要一些时间,具体取决于模型大小和网络速度。7B 模型大约需要 4GB 存储空间,13B 模型需要 8GB,70B 模型则需要 40GB 以上:
一切准备就绪后,就可以和 AI 模型聊天了:
Ollama 模型库里的不同模型各有侧重,下面这张表可以帮助你快速找到最适合自己的那一款:
| 模型名称 | 大小 | 优势 | 推荐场景 |
|---|---|---|---|
| llama3.1(8B) | 4.7GB | Meta 旗舰系列,通用能力均衡,中英文对话质量高,生态最完善 | ⭐ 首选推荐,日常对话、写作、翻译、脑暴都适合 |
| qwen:7b | 4.3GB | 阿里通义千问系列,中文理解和生成能力出色,符合国内用户表达习惯 | ⭐ 中文用户首选,写中文文案、处理中文文档、中文问答 |
| mistral(7B) | 4.1GB | Mistral AI 出品,推理速度快,在同参数量级模型中表现优异 | 追求响应速度、英文任务为主的场景 |
| gemma:2b | 1.4GB | Google 出品,体积小巧,集成显卡或无独显的电脑也能流畅运行 | 低配置电脑、入门体验、简单问答 |
| codellama(7B) | 3.8GB | Meta 出品,基于 Llama 2 微调,专注代码生成、补全和调试 | 程序员写代码、Debug、学习编程 |
| deepseek-r1:7b | 4.5GB | 深度求索出品,推理能力强,在数学和逻辑类任务上表现突出 | 数学解题、逻辑推理、编程算法 |
Ollama常用管理操作
除了下载和运行模型,Ollama 还有几个日常管理命令值得掌握。1)查看本地模型
查看本地已下载了哪些模型,执行的命令:ollama list它会列出所有模型名称、大小和修改时间,一目了然。
2)删除本地模型
如果想删除不再需要的模型释放磁盘空间,执行的命令:ollama rm 模型名比如 ollama rm gemma:2b 就能删掉对应的模型文件。
3)停用正在运行的模型
如果你在对话中想退出当前模型,输入 /bye 即可。如果想从终端外部停用某个后台运行的模型,执行的命令是:ollama stop 模型名比如 ollama stop llama3.1 就能把对应的模型进程停掉,释放内存和显存资源。
4)更新本地模型
更新已下载的模型用的命令是:ollama pull 模型名如果模型有新版发布,Ollama 也会自动下载增量更新。
Ollama常见使用问题
1)下载模型时发现速度非常慢,甚至经常中断
这是因为模型文件托管在海外服务器上,国内下载速度确实不太理想。下载中途中断了也不要紧,Ollama 支持断点续传,如果中途断了重新执行下载命令会从断点继续,不需要重新开始。
2)运行模型时提示内存不足或推理速度很慢
通常是电脑配置跟不上模型要求的缘故。大模型对内存和显存要求比较高,7B 参数的模型建议至少 8GB 内存,13B 的模型建议 16GB 以上。如果你电脑配置偏低,可以换成更小的模型,比如 gemma:2b 只需要 2GB 左右的内存就能流畅运行。另外,关闭其他正在运行的程序释放内存,也能有效改善推理速度。
3)在终端里输入中文问题后显示乱码
因为 Windows 终端默认编码的问题。在 CMD 中输入 chcp 65001 切换为 UTF-8 编码后再启动 Ollama,中文就能正常显示了。总结
Ollama 是目前在个人电脑上运行 AI 大模型最简单的方式,没有之一。从 Ollama 下载安装到跑起第一个模型,整个过程不会超过十分钟。Ollama 把原本需要大量技术储备才能完成的事情,简化成了几条命令就能搞定。无论你是 AI 爱好者、开发者,还是只想在本地安全地使用 AI 工具,Ollama 都值得一试。先从 Llama 3.1 或 Qwen 入手体验一下,你会发现在本地跑 AI 模型其实没想象中那么复杂。
 ICP备案:
ICP备案: 公安部网络备案:
公安部网络备案: