【Ollama】Ollama官网下载安装:本地AI模型部署工具使用指南
Ollama是一款开源的本地大语言模型部署工具,它的主要功能是在个人电脑上快速部署和运行各种开源大语言模型。如果你需要在本地环境中使用AI模型进行文本生成、代码编写、问答对话等任务,同时希望保护数据隐私和降低使用成本,那Ollama绝对是你理想的选择。Ollama安装包下载地址:Ollama安装包(官网正版)
Ollama提供了简单易用的命令行界面和API接口,让用户能够轻松地在本地计算机上运行Llama、Mistral、CodeLlama、Phi等主流开源大语言模型。相比云端AI服务,本地部署的模型能够确保数据完全私密,不会上传到外部服务器,同时避免了API调用费用和网络延迟问题。
Ollama支持多种操作系统平台,包括Windows、macOS和Linux,提供了统一的安装和使用体验。软件内置了模型管理功能,可以方便地下载、更新、删除不同的模型版本。用户还可以通过简单的命令与模型进行交互,或者将Ollama集成到自己的应用程序中。
目前Ollama支持的主流大语言模型包括:
| 模型系列 | 主要特点 | 适用场景 | 参数规模 |
|---|---|---|---|
| Llama 2/3 | Meta开源模型,性能优秀 | 通用对话、文本生成 | 7B/13B/70B |
| Mistral | 法国开源模型,效率高 | 代码生成、推理任务 | 7B/8x7B |
| CodeLlama | 专门针对代码优化 | 编程辅助、代码补全 | 7B/13B/34B |
| Phi-2 | 微软小模型,资源占用低 | 轻量级应用、移动设备 | 2.7B |
| Gemma | Google开源模型 | 多语言任务、研究 | 2B/7B |
对于开发者、研究人员和AI爱好者来说,Ollama提供了一个便捷的本地AI实验平台。你可以在不依赖互联网连接的情况下测试不同的模型,调整参数设置,甚至基于开源模型进行微调和定制开发。随着硬件性能的提升和模型优化技术的进步,本地运行大语言模型已经变得越来越可行。
Ollama下载
Ollama安装包下载地址:Ollama安装包(官网正版)软件完全免费开源,没有任何使用限制。下载时需要注意,Ollama提供了针对不同操作系统的安装包。Windows用户下载.exe安装程序,macOS用户下载.dmg安装包,Linux用户执行如下命令安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh
Ollama安装
Ollama的安装过程非常简单,基本上就是标准的软件安装流程。1)我使用的是 Windows 系统,下载.exe格式的可执行文件。双击这个文件启动安装程序:
2)直接点击 Install,开始安装:
3)安装完成后,点击"Cancel"按钮退出安装程序,Ollama 会自动启动:
Ollama使用教程(新手快速入门)
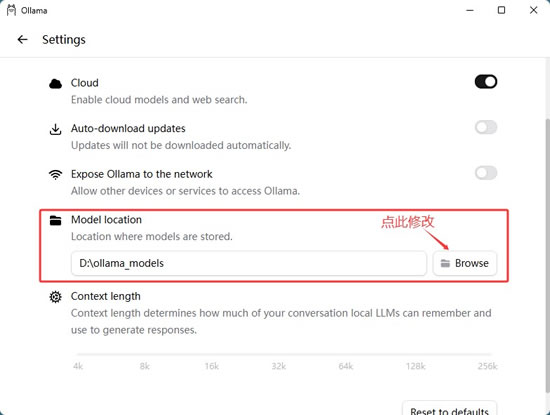
1) 修改模型存储路径(非 Windows 用户可忽略)
Ollama 默认将模型存储到 C 盘(通常为C:\Users\Administrator\.ollama\models),这对 C 盘可用容量有限的小伙伴非常不友好,我们可以手动将其修改为其它非系统盘。修改的方法很简单,进入“Settings”界面,参照下图完成修改:
2) 运行第一个模型
Ollama主要通过命令行界面进行操作。打开终端(Windows用户可以使用PowerShell或CMD),就可以开始使用Ollama了。访问 Ollama 官网模型库:https://ollama.com/library,找到你想使用的 AI 模型,比如 deepseek:
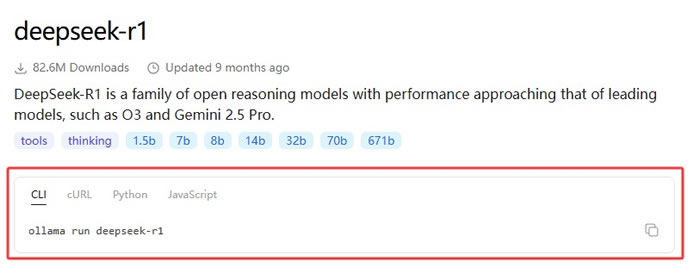
这里以 qwen2.5 模型为例,在 CMD 窗口执行如下命令:
ollama run qwen2.5
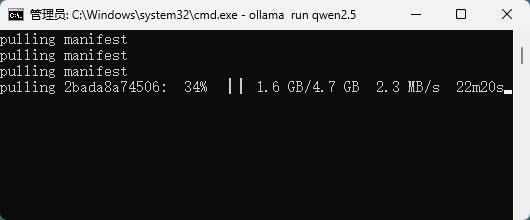
耐心等待模型下载完,下载过程可能需要一些时间,具体取决于模型大小和网络速度。7B模型大约需要4GB存储空间,13B模型需要8GB,70B模型则需要40GB以上:
一切准备就绪后,就可以和 AI 模型聊天了:
对于新手用户,建议先从较小的模型开始尝试,比如llama2:7b或mistral:7b。熟悉基本操作后,再根据需求尝试更大的模型或专用模型。
最后,在介绍几个常用的命令:
# 列出已下载的模型 ollama list # 删除模型 ollama rm <模型名> # 运行模型(交互式) ollama run <模型名> # 停止运行模型 ollama stop <模型名>
Ollama常见使用问题
Ollama下载模型速度慢怎么办?这个问题通常是因为网络连接问题或下载服务器负载较高。可以尝试几个解决方法:使用网络加速工具,更换网络环境,或者使用镜像源。有些地区还可以通过设置HTTP代理来改善下载速度。如果条件允许,可以考虑手动下载模型文件,然后导入到Ollama中。Ollama运行模型时内存不足怎么办?首先检查一下电脑的物理内存和虚拟内存设置。运行大模型需要足够的内存空间,如果内存不足,可以尝试几个优化方法:使用参数更小的模型版本,调整Ollama的内存限制设置,增加系统虚拟内存,或者关闭其他占用内存的应用程序。对于有独立显卡的电脑,确保Ollama正确识别并使用GPU内存。
Ollama无法识别GPU怎么办?首先确认电脑是否安装了兼容的NVIDIA显卡和驱动程序。运行"nvidia-smi"命令检查GPU状态。如果Ollama没有自动使用GPU,可以尝试手动设置环境变量:在启动Ollama前设置OLLAMA_GPU_LAYER=1。还可以检查CUDA和cuDNN库是否正确安装。某些旧型号显卡可能不完全兼容,需要参考官方文档中的硬件要求。
Ollama的API接口无法访问怎么办?首先确认Ollama服务是否正在运行。在终端中运行"ollama serve"启动服务。检查防火墙设置,确保11434端口没有被阻止。如果是在Docker容器中运行,需要正确映射端口。还可以检查Ollama的配置文件,确认API服务绑定到了正确的网络接口。默认情况下,Ollama API只监听本地回环地址(127.0.0.1),如果需要从其他设备访问,需要修改绑定设置。
Ollama模型响应速度慢怎么办?模型响应速度受多个因素影响:模型大小、硬件性能、参数设置等。可以尝试几个优化方法:使用量化版本的模型(如q4_0、q8_0),这些版本在保持较好性能的同时大幅减少了资源占用。调整生成参数,如减少max_tokens值。确保Ollama正确使用了GPU加速。对于CPU运行的情况,可以尝试使用性能更好的CPU或增加线程数设置。
Ollama下载安装教程总结
Ollama作为一款开源的本地大语言模型部署工具,为个人和组织提供了便捷的AI能力接入方案。通过使用Ollama,用户可以在本地环境中运行各种开源大语言模型,享受AI带来的便利,同时确保数据隐私和安全。对于个人用户,Ollama提供了简单易用的界面和丰富的模型选择,可以在不依赖云端服务的情况下体验AI技术。对于开发者,Ollama的API接口和可扩展架构便于集成到各种应用程序中。对于研究人员,本地部署的环境便于进行模型测试、参数调整和实验研究。
Ollama下载安装过程简单直接,使用体验稳定可靠。随着开源模型的不断发展和硬件性能的提升,本地运行大语言模型的门槛正在逐渐降低。无论是简单的文本对话还是复杂的专业应用,Ollama都能提供合适的解决方案。
掌握Ollama的使用技巧需要一些学习和实践,但投入是值得的。一个熟练的Ollama用户可以在本地环境中构建强大的AI应用,探索人工智能技术的各种可能性。随着AI技术的普及和发展,掌握本地模型部署能力将成为一项重要的技术技能。
 ICP备案:
ICP备案: 公安部网络备案:
公安部网络备案: